1. 개념적 이해 : 머신러닝의 핵심 이론 및 기법
머신러닝을 트레이딩 및 투자에 적용할 때 중요한 개념을 정리하면 다음과 같다.

① 지도학습(Supervised Learning)과 비지도학습(Unsupervised Learning)

지도학습(Supervised Learning) 기반 트레이딩 전략
머신러닝에서 지도학습(Supervised Learning) 은 입력 데이터(특징, Features)와 정답(레이블, Labels) 을 이용해 모델을 학습시키는 방식이다.
트레이딩에서는 주가 방향성 예측, 옵션 가격 예측, 포트폴리오 최적화 등에 활용된다.
ⓐ 지도학습을 활용한 트레이딩 전략 개요
📌 지도학습이 트레이딩에 적합한 이유
과거 데이터를 기반으로 시장 패턴을 학습하여 가격 변동을 예측
특정 자산(주식, 옵션, 외환 등)의 미래 움직임을 예측하여 거래 전략 수립
정형 데이터(가격, 거래량)뿐만 아니라, 뉴스, 소셜 미디어 데이터를 활용한 감성 분석 가능
📌 주요 활용 분야
활용 분야 설명 적용 모델
주가 방향성 예측 단기(1일~1주), 중기(1개월), 장기(6개월 이상) 주가 방향성 예측 Random Forest, XGBoost, LSTM
옵션 가격 예측 블랙-숄즈 모델을 보완하여 옵션 가격을 정밀 예측 Random Forest, DNN(Deep Neural Network)
알고리즘 트레이딩 자동화된 매매 전략 개발 및 신호 생성 CNN, Transformer
ETF 및 포트폴리오 최적화 투자 자산 배분 및 리스크 조절 XGBoost, Reinforcement Learning
ⓑ 주가 방향성 예측 : 머신러닝 모델 적용 방법
📌 문제 정의:
주가(Stock Price)가 다음 거래일(혹은 특정 기간) 동안 상승할지 하락할지 예측
이진 분류(Binary Classification) 문제:
상승(1) / 하락(0)
회귀(Regression) 문제:
특정 기간 후의 주가 예측
㉮ 데이터 수집 및 전처리
💡 필요한 데이터 유형
| 데이터 유형 | 설명 |
| 가격 데이터 (OHLCV) | Open, High, Low, Close, Volume (시가, 고가, 저가, 종가, 거래량) |
| 기술적 지표 (TA) | 이동평균(MA), RSI, MACD, 볼린저 밴드 등 |
| 파생 데이터 | 변동성, 이동 평균 크로스오버, 트렌드 강도 등 |
| 감성 분석 데이터 | 뉴스, 소셜 미디어 감성 점수 |
| 거시경제 데이터 | 금리, 유가, 경제 성장률 |

㉯ 특징(Feature) 엔지니어링
💡 주요 특징(Feature) 변환 방법
변동성 특징 : ATR(Average True Range), Bollinger Bands 등
추세 특징 : 이동 평균(MA), MACD(Moving Average Convergence Divergence)
거래량 특징 : OBV(On-Balance Volume), AD(Accumulation Distribution)
감성 분석 특징 : 뉴스 기사 및 소셜 미디어 감성 점수
📌 예제 코드 (특징 생성)
python
복사편집
import pandas as pd
import numpy as np
import ta # 기술적 분석 라이브러리
# 데이터 로드 (예: Yahoo Finance 데이터)
df = pd.read_csv('stock_data.csv')
# 기술적 지표 추가
df['rsi'] = ta.momentum.RSIIndicator(df['close']).rsi()
df['macd'] = ta.trend.MACD(df['close']).macd()
df['bollinger_hband'] = ta.volatility.BollingerBands(df['close']).bollinger_hband()
df['volatility'] = ta.volatility.AverageTrueRange(df['high'], df['low'], df['close']).average_true_range()
# 결측값 제거
df = df.dropna()

㉰ 지도학습 모델 학습 및 적용
▣ 랜덤 포레스트(Random Forest) 기반 주가 예측
📌 랜덤 포레스트는 트리 기반 모델로, 비선형 관계를 잘 학습하며 주가 방향성 예측에 활용됨
📌 랜덤 포레스트의 장점 :
✔ 과적합(Overfitting) 방지
✔ 다중 특징(Feature) 간의 상호 작용을 효과적으로 처리
📌 실전 코드 (Random Forest 적용)
python
복사편집
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 데이터 준비
X = df[['rsi', 'macd', 'bollinger_hband', 'volatility']] # 특징 데이터
y = np.where(df['close'].shift(-1) > df['close'], 1, 0) # 상승(1), 하락(0)
# 훈련 및 테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 랜덤 포레스트 모델 학습
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 예측 및 성능 평가
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f'모델 정확도: {accuracy:.2f}')
▣ LSTM(Long Short-Term Memory) 기반 주가 예측
📌 LSTM은 과거 가격 패턴을 학습하여 시계열 예측에 적합한 모델
기존 모델의 한계: 전통적인 ML 모델은 과거 데이터의 시간 종속성(Temporal Dependency) 을 고려하지 못함
LSTM 활용: 주가 데이터의 연속적인 변화를 학습하여 단기 및 중기 가격 예측에 강력한 성능 발휘
📌 실전 코드 (LSTM 적용)
python
복사편집
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from sklearn.preprocessing import MinMaxScaler
# 데이터 스케일링
scaler = MinMaxScaler()
X_scaled = scaler.fit_transform(X)
# LSTM 입력 형태 변환
X_lstm = X_scaled.reshape((X_scaled.shape[0], 1, X_scaled.shape[1]))
# LSTM 모델 구축
model = Sequential([
LSTM(50, return_sequences=True, input_shape=(1, X_lstm.shape[2])),
Dropout(0.2),
LSTM(50, return_sequences=False),
Dense(1, activation='sigmoid')
])
# 모델 컴파일 및 학습
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.fit(X_lstm, y, epochs=50, batch_size=32, verbose=1)
# 예측
y_pred = model.predict(X_lstm)

ⓒ 옵션 가격 예측 : 머신러닝 적용
📌 옵션 가격 예측이 어려운 이유
전통적인 블랙-숄즈(Black-Scholes) 모델은 시장의 복잡한 비효율성을 반영하지 못함
옵션 가격은 변동성, 금리, 만기, 수요-공급 등 다양한 요인에 영향을 받음
💡 머신러닝 적용 방법
랜덤 포레스트를 이용한 옵션 가격 예측
옵션의 내재가치(Intrinsic Value), 시간가치(Time Value) 등을 특징으로 사용
딥러닝(DNN, LSTM) 모델을 활용한 변동성 예측
VIX 지수(시장 변동성)를 반영하여 옵션 가격 모델 최적화
결론: 머신러닝을 활용한 트레이딩 전략 최적화
✔ 랜덤 포레스트, XGBoost: 비선형적 관계 학습을 통해 단기 트레이딩 신호 생성
✔ LSTM, Transformer: 시계열 종속성을 고려하여 주가 패턴을 정밀 분석
✔ 딥러닝 기반 옵션 가격 모델: 블랙-숄즈 모델을 보완하여 옵션 트레이딩 최적화
🚀 이러한 기법을 조합하면, 데이터 기반으로 리스크를 최소화하면서도 초과 수익(Alpha)을 창출하는 전략을 구축할 수 있습니다!
★ 지도학습 : 주가 방향성 예측, 옵션 가격 예측 등에 사용 (예: Random Forest, LSTM)

② 비지도학습 : 군집 분석을 통해 투자 스타일 분류, 이상치 탐지(Anomaly Detection)
비지도학습(Unsupervised Learning)은 정답(레이블)이 없는 데이터에서 패턴을 찾아내는 방법으로, 트레이딩에서는 군집 분석(Clustering)과 이상 탐지(Anomaly Detection) 를 활용하여 투자 스타일 분석 및 시장 이상 신호 탐지에 응용할 수 있다.
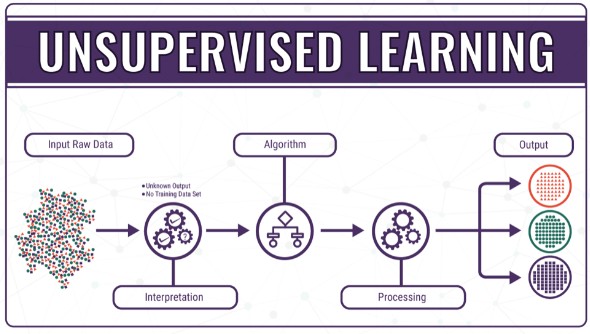
ⓐ 비지도학습(Unsupervised Learning) 기반을 활용한 트레이딩 전략 개요
📌 비지도학습이 트레이딩에 적합한 이유
투자자의 매매 패턴을 분석하여 투자 스타일 분류
시장에서 이상 거래(급등/급락, 조작된 거래 등) 탐지
군집 분석을 활용하여 종목 간 유사성 분석 및 최적 포트폴리오 구성
정형 데이터(가격, 거래량)뿐만 아니라, 비정형 데이터(뉴스, 소셜 미디어 등)에도 적용 가능
📌 주요 활용 분야
| 활용 분야 | 설명 | 적용 모델 |
| 투자 스타일 분류 | 투자자(혹은 종목)별 거래 패턴 분석 | K-Means, DBSCAN, Hierarchical Clustering |
| 시장 이상치 탐지 | 갑작스러운 가격 변동, 조작 가능성 탐색 | Isolation Forest, One-Class SVM, Autoencoder |
| 섹터/산업별 주식 군집 분석 | 종목 간 유사성 분석 및 포트폴리오 구성 | PCA + K-Means, Hierarchical Clustering |
| 이상 거래량 탐지 | 급등주, 공매도 급증 탐색 | Anomaly Detection, Bayesian Methods |

ⓑ 투자 스타일 분석 : 군집 분석(Clustering) 활용
㉮ 투자자 스타일을 군집화하여 트레이딩 전략 최적화
📌 문제 정의:
기관 투자자 vs. 개별 투자자의 매매 패턴이 다름
투자 스타일(모멘텀 투자자, 가치 투자자, 고빈도 트레이더 등)을 분류하여 최적의 투자 전략 설계
📌 적용 모델:
K-Means Clustering: 투자자의 거래 패턴을 클러스터링
Hierarchical Clustering: 종목 간 유사성 분석 및 투자 스타일 탐색

㉯ 실전 코드 : K-Means를 이용한 투자자 스타일 분석
💡 데이터 수집
| 투자 지표 | 설명 |
| 거래 빈도(Frequency) | 하루/한 달 동안 거래 횟수 |
| 평균 보유 기간(Holding Period) | 평균적으로 종목을 보유하는 기간 |
| 손익비율(Profit/Loss Ratio) | 수익 대비 손실 비율 |
| 포트폴리오 다각화 | 평균 보유 종목 수 |
📌 예제 코드: 투자자 스타일 클러스터링
python
복사편집
import pandas as pd
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
# 가상의 투자자 데이터 생성
data = {'trade_frequency': [5, 20, 50, 2, 15, 100, 7, 60, 80, 30],
'holding_period': [30, 10, 2, 60, 20, 1, 40, 3, 5, 15],
'profit_loss_ratio': [1.2, 0.8, 1.5, 2.0, 1.1, 0.7, 1.8, 1.0, 1.3, 0.9]}
df = pd.DataFrame(data)
# K-Means 클러스터링
kmeans = KMeans(n_clusters=3, random_state=42)
df['cluster'] = kmeans.fit_predict(df[['trade_frequency', 'holding_period', 'profit_loss_ratio']])
# 시각화
plt.scatter(df['trade_frequency'], df['holding_period'], c=df['cluster'], cmap='viridis')
plt.xlabel('거래 빈도')
plt.ylabel('평균 보유 기간')
plt.title('투자자 스타일 클러스터링')
plt.show()
📌 결과 해석:
클러스터 1: 단기 트레이더 (거래 빈도 높고, 보유 기간 짧음)
클러스터 2: 장기 투자자 (거래 빈도 낮고, 보유 기간 김)
클러스터 3: 중기 스윙 트레이더
📌 트레이딩 전략 적용:
단기 트레이더에게는 고빈도 트레이딩 전략(HFT, High-Frequency Trading) 추천
장기 투자자에게는 가치주 분석 및 포트폴리오 리밸런싱 전략 적용

ⓒ 이상 거래 탐지(Anomaly Detection) : 시장 조작 및 급등주 탐색
㉮ 이상치 탐지의 필요성
📌 문제 정의:
금융 시장에서는 급격한 가격 변동, 조작된 거래, 허위 유동성 등의 이상 징후가 존재
머신러닝을 활용하여 이상 거래를 자동 탐지하고 조기 경보 시스템 구축 가능
📌 적용 모델:
Isolation Forest: 이상 거래를 감지하는 앙상블 모델
One-Class SVM: 정상 거래 패턴을 학습하고 이상 탐지
Autoencoder: 딥러닝 기반 이상 탐지 모델

㉯ 실전 코드 : Isolation Forest를 활용한 이상 거래 탐지
💡 데이터 수집
| 거래 지표 | 설명 |
| 거래량(Volume) | 특정 종목의 거래량 |
| 가격 변동성(Volatility) | 주가의 급등/급락 여부 |
| 매수/매도 비율 | 특정 시간 동안 매수 vs 매도 비율 |
📌 예제 코드: Isolation Forest를 활용한 이상 거래 탐지
python
복사편집
from sklearn.ensemble import IsolationForest
# 가상의 이상 거래 데이터 생성
data = {'volume': [1000, 500, 700, 1200, 6000, 200, 900, 300, 100000, 450],
'volatility': [0.02, 0.015, 0.018, 0.03, 0.1, 0.005, 0.025, 0.012, 0.5, 0.03]}
df = pd.DataFrame(data)
# Isolation Forest 모델 적용
iso_forest = IsolationForest(contamination=0.1, random_state=42)
df['anomaly'] = iso_forest.fit_predict(df[['volume', 'volatility']])
# 이상 거래 탐지 결과 출력
print(df[df['anomaly'] == -1]) # 이상 거래로 판별된 데이터
📌 결과 해석 :
거래량이 갑자기 급증한 경우 (예: 한 번에 10만 주 거래) → 이상 거래로 탐지
변동성이 비정상적으로 높은 경우 (예: 하루 변동률 50%) → 시장 조작 가능성
📌 트레이딩 전략 적용:
급등주(Short Squeeze) 탐색: 이상 거래 감지 후, 공매도 비율과 비교하여 매수 기회 포착
리스크 관리: 비정상적인 거래량 급증 종목에 대해 매매 신호 제한

결론 : 비지도학습을 활용한 트레이딩 최적화
✔ 군집 분석(Clustering): 투자 스타일을 구분하여 맞춤형 트레이딩 전략 적용
✔ 이상치 탐지(Anomaly Detection): 급등주, 허위 거래, 시장 조작 등을 실시간 감지
✔ 강화된 리스크 관리: 이상 거래 탐지를 활용한 포트폴리오 방어 전략 구축
🚀 이러한 기법을 활용하면 시장의 보이지 않는 패턴을 발견하고, 초과 수익(Alpha)을 창출할 수 있습니다!
'억만장자' 카테고리의 다른 글
| 머신러닝 딥러닝 이미지 프로세싱 기업 솔루션을 구축하고 설계한다 4 (0) | 2025.02.09 |
|---|---|
| 머신러닝 딥러닝 이미지 프로세싱 기업 솔루션을 구축하고 설계한다 3 (0) | 2025.02.09 |
| 머신러닝 딥러닝 이미지 프로세싱 기업 솔루션을 구축하고 설계한다 1 (1) | 2025.02.09 |
| 글로벌시대 3년 내 억만장자가 된다. (2) | 2024.12.29 |
| 100세 시대 경제적 자유를 누리는 인생설계 2 (7) | 2024.12.16 |



