1. 시계열 데이터 처리 (Time-Series Analysis) 기반 트레이딩 전략
주가 데이터는 일반적인 머신러닝 데이터와 다르게 시간 의존성(Temporal Dependency) 이 큼. 주가 데이터는 시간 의존성(Temporal Dependency) 이 강하기 때문에 일반적인 머신러닝 모델(Random Forest, XGBoost 등)보다 시계열 특성을 반영하는 딥러닝 모델(LSTM, Transformer 등) 이 더 적합하다.

① 시계열 데이터의 특징과 분석 전략
📌 시계열 데이터의 주요 특성
자기상관성(Autocorrelation): 이전 가격이 미래 가격에 영향을 미침
트렌드(Trend): 일정 기간 동안 지속적인 상승/하락 경향
계절성(Seasonality): 일정 주기마다 반복되는 패턴 (예: 월말 상승 효과)
비정상성(Non-Stationarity): 시간에 따라 평균과 분산이 변하는 특성
📌 머신러닝 적용 시 고려할 점
데이터의 시간 순서 유지 필요 (일반 ML 모델은 랜덤 샘플링이 가능하지만, 시계열 데이터는 불가능)
과거 데이터가 미래 데이터를 예측하는 데 중요한 역할을 함
과적합(Overfitting) 방지를 위해 특징 엔지니어링 및 정규화 필요
📌 주요 활용 분야
| 활용 분야 | 설명 | 적용 모델 |
| 단기 가격 예측 | 1~10일 이내의 주가 변동 예측 | LSTM, GRU, Transformer |
| 변동성 예측 | 주가 변동성(Volatility) 및 위험 분석 | GARCH, Bayesian Networks |
| 이상 탐지(Anomaly Detection) | 급등락 패턴 감지, 이상 거래 탐색 | Autoencoder, Isolation Forest |
| 포트폴리오 최적화 | 시계열 데이터 기반 최적 자산 배분 | Reinforcement Learning (RL) |
② 시계열 예측을 위한 데이터 전처리
LSTM(Long Short-Term Memory), Transformer 모델을 활용한 고급 시계열 예측 기법 필요
📌 주요 데이터 변환 기법
정규화(Normalization): LSTM, Transformer 모델에서 안정적인 학습을 위해 데이터 크기를 조정
차분(Differencing): 데이터의 비정상성을 제거하여 정상성을 확보
시간 창(Windowing) 생성: 과거 N일치 데이터를 하나의 입력으로 변환
📌 실전 코드 : 데이터 전처리
python
복사편집
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
# 데이터 로드 (예: Yahoo Finance 데이터)
df = pd.read_csv('stock_data.csv')
# 날짜 정렬 및 인덱스 설정
df['date'] = pd.to_datetime(df['date'])
df.set_index('date', inplace=True)
# 정규화
scaler = MinMaxScaler()
df[['close']] = scaler.fit_transform(df[['close']])
# 차분 변환 (1차 차분)
df['close_diff'] = df['close'].diff()
df.dropna(inplace=True)
# LSTM 모델을 위한 시계열 데이터 윈도우 생성
def create_sequences(data, seq_length):
X, y = [], []
for i in range(len(data) - seq_length):
X.append(data[i:i+seq_length])
y.append(data[i+seq_length])
return np.array(X), np.array(y)
# 시계열 데이터 변환
seq_length = 10 # 최근 10일 데이터를 입력으로 사용
X, y = create_sequences(df['close'].values, seq_length)
# 학습 데이터와 테스트 데이터 분리
train_size = int(len(X) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
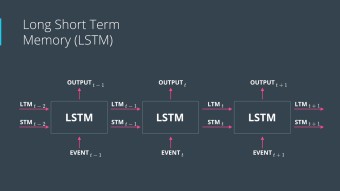
③ LSTM(Long Short-Term Memory) 기반 주가 예측
📌 LSTM의 장점
과거 데이터의 장기 의존성(Long-Term Dependency) 문제 해결
과거의 중요한 정보를 유지하면서 불필요한 정보는 제거
변동성이 큰 시장에서도 안정적인 예측 성능 제공
📌 LSTM 모델 구축 및 학습
python
복사편집
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
# LSTM 모델 생성
model = Sequential([
LSTM(50, return_sequences=True, input_shape=(seq_length, 1)), # 입력: 최근 10일 가격 데이터
Dropout(0.2),
LSTM(50, return_sequences=False),
Dense(1, activation='linear') # 가격 예측이므로 회귀 모델 사용
])
# 모델 컴파일
model.compile(optimizer='adam', loss='mse')
# 모델 학습
model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_test, y_test), verbose=1)
# 예측 수행
predictions = model.predict(X_test)
📌 결과 해석 및 개선 방법
기본적인 LSTM 모델이지만 Dropout을 적용하여 과적합 방지
추가적으로 GRU(Gated Recurrent Unit) 을 사용하여 성능을 비교 가능
시장 데이터의 특성을 반영하여 기술적 지표(RSI, MACD 등)도 입력 변수로 추가 가능

④ Transformer 기반 주가 예측 (Attention Mechanism 활용)
📌 Transformer 모델이 필요한 이유
LSTM은 순차적으로 데이터를 처리해야 하므로 훈련 속도가 느림
Transformer는 병렬 연산이 가능하여 더 빠른 학습 속도와 성능 제공
주식 시장의 다양한 요인을 동시에 분석할 수 있는 멀티-헤드 어텐션(Multi-Head Attention) 적용 가능
📌 Transformer 모델 구축
python
복사편집
import tensorflow as tf
from tensorflow.keras.layers import Dense, MultiHeadAttention, LayerNormalization, Dropout, Input
from tensorflow.keras.models import Model
# Transformer 블록 정의
def transformer_block(inputs, head_size, num_heads, ff_dim, dropout=0.1):
x = MultiHeadAttention(key_dim=head_size, num_heads=num_heads)(inputs, inputs)
x = Dropout(dropout)(x)
x = LayerNormalization(epsilon=1e-6)(x)
res = x + inputs # Residual Connection
x = Dense(ff_dim, activation="relu")(res)
x = Dropout(dropout)(x)
x = Dense(inputs.shape[-1])(x)
x = LayerNormalization(epsilon=1e-6)(x)
return x + res # 최종 Residual Connection
# Transformer 모델 생성
input_layer = Input(shape=(seq_length, 1))
x = transformer_block(input_layer, head_size=64, num_heads=4, ff_dim=128)
x = Dense(1, activation="linear")(x) # 회귀 예측
# 모델 컴파일 및 학습
model = Model(inputs=input_layer, outputs=x)
model.compile(loss="mse", optimizer="adam")
model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_test, y_test), verbose=1)
# 예측 수행
predictions = model.predict(X_test)
📌 Transformer의 강점
주가 패턴에서 장기적인 의존성을 학습하는 데 뛰어남
LSTM 대비 빠른 학습 속도 및 병렬 연산 가능
다양한 기술적 지표 및 뉴스 데이터를 추가 입력으로 활용 가능

⑤ 시계열 데이터 분석을 활용한 투자 전략
💡 머신러닝 예측을 트레이딩 전략에 적용하는 방법
| 전략 유형 | 설명 | 적용 모델 |
| 모멘텀 트레이딩 | 주가 상승/하락 예측 후 단기 매매 | LSTM, Transformer |
| 변동성 돌파 전략 | 일정 변동성 이상이면 매매 실행 | GARCH, Bayesian Volatility Models |
| 롱-숏 전략 | 상승 가능성이 높은 종목 롱(Long), 하락 예상 종목 숏(Short) | 강화학습(RL) |

결론 : 머신러닝 기반 시계열 분석을 활용한 트레이딩 최적화
✔ LSTM : 단기 및 중기 가격 예측에 강력한 성능 제공
✔ Transformer : 장기적인 패턴을 학습하며 높은 확장성 제공
✔ 시계열 분석과 트레이딩 전략 결합 : 머신러닝을 활용하여 변동성 리스크를 줄이면서도 초과 수익(Alpha) 창출
🚀 이러한 모델을 실전 투자 전략에 적용하면 데이터 기반 트레이딩의 강력한 경쟁력을 확보할 수 있다!

'억만장자' 카테고리의 다른 글
| 경제적 자유를 누리는 백만장자의 인생청사진 1 (0) | 2025.02.10 |
|---|---|
| 머신러닝 딥러닝 이미지 프로세싱 기업 솔루션을 구축하고 설계한다 4 (0) | 2025.02.09 |
| 머신러닝 딥러닝 이미지 프로세싱 기업 솔루션을 구축하고 설계한다 2 (1) | 2025.02.09 |
| 머신러닝 딥러닝 이미지 프로세싱 기업 솔루션을 구축하고 설계한다 1 (1) | 2025.02.09 |
| 글로벌시대 3년 내 억만장자가 된다. (2) | 2024.12.29 |



